
Machine learning is transforming industries and redefining possibilities. It enables systems to learn from data, identify patterns, and make decisions with minimal human input. This guide will break down its essential concepts, techniques, and uses, making it simple and relatable for beginners. It is a powerful tool that has reshaped technology, and understanding it can open up new opportunities. Let’s dive into the basics of this revolutionary technology to understand why it matters and how it works.
1. What is Machine Learning?

Machine learning is a subset of artificial intelligence. It involves systems learning from data to improve at specific tasks. Unlike traditional programming, it doesn’t require explicit instructions to perform tasks. Instead, algorithms detect patterns and make predictions. This adaptability makes machine learning highly versatile, allowing it to solve complex problems across various domains, from healthcare to finance.
How It Works
At its core, machine learning depends on data and algorithms. Data feeds into the system, and the algorithm processes it to generate insights. Over time, the system improves its accuracy by learning from mistakes. For example, if the system misclassifies data initially, adjustments are made based on feedback, ensuring better predictions in the future. This process makes the system smarter and more efficient with use.
You can also watch this video on how to learn machine learning in 2025:
Types of Machine Learning
Machine learning is divided into three main categories:
- Supervised Learning: Algorithms learn from labelled data, where the input and the expected output are known.
- Unsupervised Learning: Algorithms use unlabeled data to find patterns and structures without predefined outputs.
- Reinforcement Learning: Algorithms learn through interaction and feedback, optimising actions to gain rewards. This type is often used in areas like robotics and gaming, where the system adapts to changing environments.
2. Key Terminologies
Algorithm
An algorithm is a set of rules guiding how data is analyzed. It defines the steps needed to solve a specific problem. For instance, an algorithm might determine whether an email is spam by analyzing its content and sender details. These rules are the foundation of machine learning systems.
Model
A model is the result of an algorithm after training. It’s what makes predictions or decisions based on new data. For example, a weather prediction model uses past weather data to forecast future conditions. The accuracy of the model depends on how well it’s trained and the quality of the data it uses.
Training and Testing Data
Training data teaches the model while testing data checks its accuracy. This separation ensures reliable performance. For instance, if you’re teaching a model to recognize animals, you’d use one set of images (training data) to teach it and another set (testing data) to evaluate how well it learned.
Features and Labels
Features are input variables (e.g., age, income). Labels are the output the model predicts (e.g., loan approval). Features provide the necessary context, while labels give the model a target to aim for. Together, they form the basis for the model’s learning process.
3. Types of Machine Learning

Supervised Learning
Supervised learning uses labelled data, meaning each input has a known output. For example, predicting house prices based on size and location. The algorithm learns by comparing its predictions to the known outputs and adjusting accordingly. Common tasks include:
- Classification: Sorting data into categories (e.g., spam or not spam). This is used in email filtering.
- Regression: Predicting continuous values (e.g., stock prices). Regression models analyze trends and relationships to make predictions.
Unsupervised Learning
Unsupervised learning works with unlabeled data. The goal is to uncover hidden patterns or structures. For example, it can group customers based on shopping habits without prior labels. Popular techniques include:
- Clustering: Grouping similar data points (e.g., customer segmentation). This helps businesses tailor their services to different groups.
- Dimensionality Reduction: Simplifying data while retaining important information (e.g., PCA). This technique reduces complexity, making large datasets easier to analyze and visualize.
Reinforcement Learning
Reinforcement learning trains models by interacting with an environment. The model learns by trial and error, optimizing its actions to maximize rewards. For example, a robot learns to navigate a maze by receiving rewards for reaching the goal. This type of learning is dynamic and adapts to changing scenarios, making it ideal for complex tasks.
4. How Machine Learning Works?
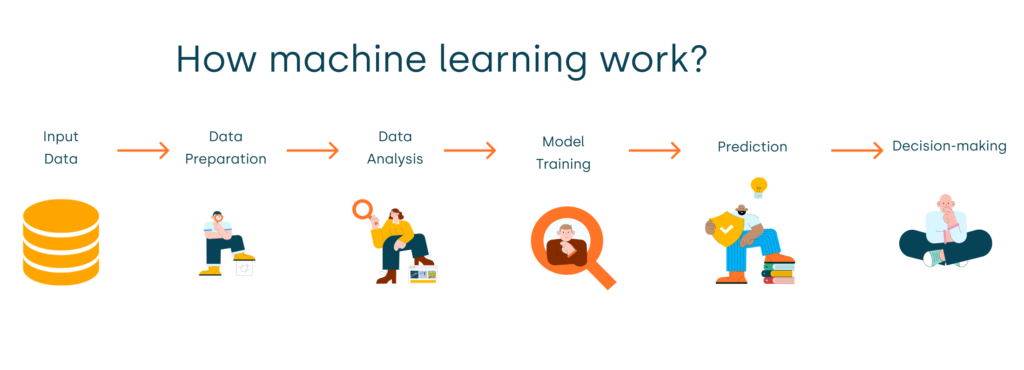
Machine learning is like teaching a computer to recognize patterns and make decisions. Here’s a simple process of how it works, explained step by step:
1. Data Collection
- What does this mean?
The first step is to gather information (data). This data is like the examples a computer needs to learn. - For example: If you’re training a computer to recognize cats, you collect pictures of cats.
- Where does the data come from?
Data can come from many sources, such as:- Surveys: Asking people questions.
- Databases: Stored information, like weather reports.
- Sensors: Devices that measure things, like temperature or movement.
- Why is this important?
The more accurate and complete the data, the better the computer will learn.
2. Data Preprocessing
- What does this mean?
The raw data you collect might not be perfect—it could have mistakes, missing pieces, or be messy. Preprocessing is like cleaning up a messy room.
- How do you clean the data?
- Remove duplicate entries (like identical survey responses).
- Fill in missing information (e.g., use averages for empty values).
- Standardize the data (e.g., making sure all dates follow the same format).
- Why is this important?
Clean, organized data helps the computer learn better and make fewer mistakes.
3. Model Training
- What does this mean?
Now the computer is ready to learn! Training means teaching the computer by showing it examples (called training data).
- How does the computer learn?
- It looks for patterns and relationships in the data.
- For example: You might learn that bigger houses usually cost more.
- Why is this important?
This step creates the actual “model” (the brain of the computer), which will be used to make predictions or decisions.
4. Model Evaluation
- What does this mean?
After training, you need to check if the computer really learned well. This is like taking a test in school to see if you understood the lessons.
- How is the model tested?
- You give the computer new data it hasn’t seen before and check how well it predicts.
- For example: If the model was trained to predict house prices, you test it with data about houses not used during training.
- What do you look for?
- Metrics like accuracy (how often it’s right) or precision (how specific it is).
- If the results are bad, you go back and adjust things, like using more data or a different algorithm.
5. Deployment
- What does this mean?
Once the model works well, you use it in real life. This is when the computer starts doing useful tasks.
- Examples of deployment:
- An online store might use a model to recommend products you’ll like.
- A phone app might use a model to identify objects in photos.
- Why is this important?
Deployment is the final step where the model starts helping people or solving problems.
5. Common Algorithms and Techniques

1. Linear Regression
Linear regression predicts continuous outcomes by finding relationships between variables. For example, estimating sales based on advertising spend. It is one of the simplest yet most effective tools for analyzing trends and making forecasts.
2. Decision Trees
Decision trees are flowchart-like models. They split data based on conditions to make predictions. For instance, a decision tree might classify emails by analyzing words and the sender’s reputation. They’re intuitive and work well with structured data.
3. Support Vector Machines (SVM)
SVMs are powerful classification tools. They create boundaries that separate data into different categories. For example, they can classify whether a tumor is benign or malignant based on patient data. SVMs are highly effective for small, well-defined datasets.
4. Neural Networks
Neural networks mimic the human brain. They process data in layers to identify complex patterns, making them ideal for image and speech recognition. For example, they enable voice assistants like Siri to understand spoken commands. Neural networks are at the heart of many modern AI applications.
6. Difference Between Machine Learning and Artificial Intelligence

Machine learning (ML) and artificial intelligence (AI) are often used interchangeably, but they are distinct concepts within the broader field of technology. Understanding the differences between the two is crucial for anyone delving into these subjects.
1. Definitions
- Artificial Intelligence (AI):
AI refers to the broader concept of creating machines or systems capable of performing tasks that would typically require human intelligence. These tasks include reasoning, problem-solving, decision-making, and understanding natural language. AI aims to mimic human cognitive abilities. - Machine Learning (ML):
ML is a subset of AI that focuses on enabling machines to learn from data and improve their performance over time without being explicitly programmed for every task. It uses algorithms to analyze patterns in data and make predictions or decisions based on what it has learned.
2. Scope
- AI:
AI encompasses a wide range of techniques and technologies, including robotics, natural language processing (NLP), expert systems, and machine learning. AI can be classified into:- Narrow AI: Systems designed for specific tasks, like virtual assistants (e.g., Siri).
- General AI: Hypothetical systems that can perform any intellectual task like a human.
- ML:
ML is more focused and deals specifically with creating models that can process data to make predictions or decisions. ML does not aim to replicate all aspects of human intelligence but focuses on learning from data.
3. How They Work
- AI:
AI systems work by combining multiple approaches, such as rule-based systems, logic, and neural networks, to perform intelligent tasks. For example, an AI chatbot may use predefined rules alongside ML models to answer questions. - ML:
ML relies heavily on data. The process involves:- Feeding data into an algorithm.
- Allowing the model to learn patterns in the data.
- Using the trained model to make predictions on new data.
For example, an ML model for email filtering learns to distinguish spam emails from legitimate ones by analyzing labelled examples.
4. Dependency on Data
- AI:
AI can function using predefined rules and logic even without large amounts of data. For example, an expert system may use if-then rules to diagnose diseases. - ML:
ML is highly dependent on data. The quality and quantity of data directly affect the model’s performance. Without sufficient data, ML models cannot learn effectively.
5. Real-World Examples
- AI:
- Virtual assistants like Alexa and Google Assistant.
- Autonomous vehicles that combine ML, sensors, and decision-making algorithms.
- Chess-playing programs that use strategies and logic to outsmart opponents.
- ML:
- Recommendation systems on platforms like Netflix or Amazon that suggest content or products.
- Fraud detection in banking by analyzing transaction patterns.
- Medical image analysis to identify diseases like cancer.
6. Goal
- AI:
The ultimate goal of AI is to create systems that can mimic human intelligence and possibly surpass it in some domains. It focuses on broader cognitive functions, such as reasoning and decision-making. - ML:
The goal of ML is narrower: to enable systems to learn from data and improve over time, focusing primarily on prediction and classification tasks.
In short, while machine learning is a part of artificial intelligence, artificial intelligence is a broader concept encompassing many other techniques beyond just machine learning. Understanding their relationship helps clarify their roles and potential in shaping the future of technology.
7. Applications of Machine Learning
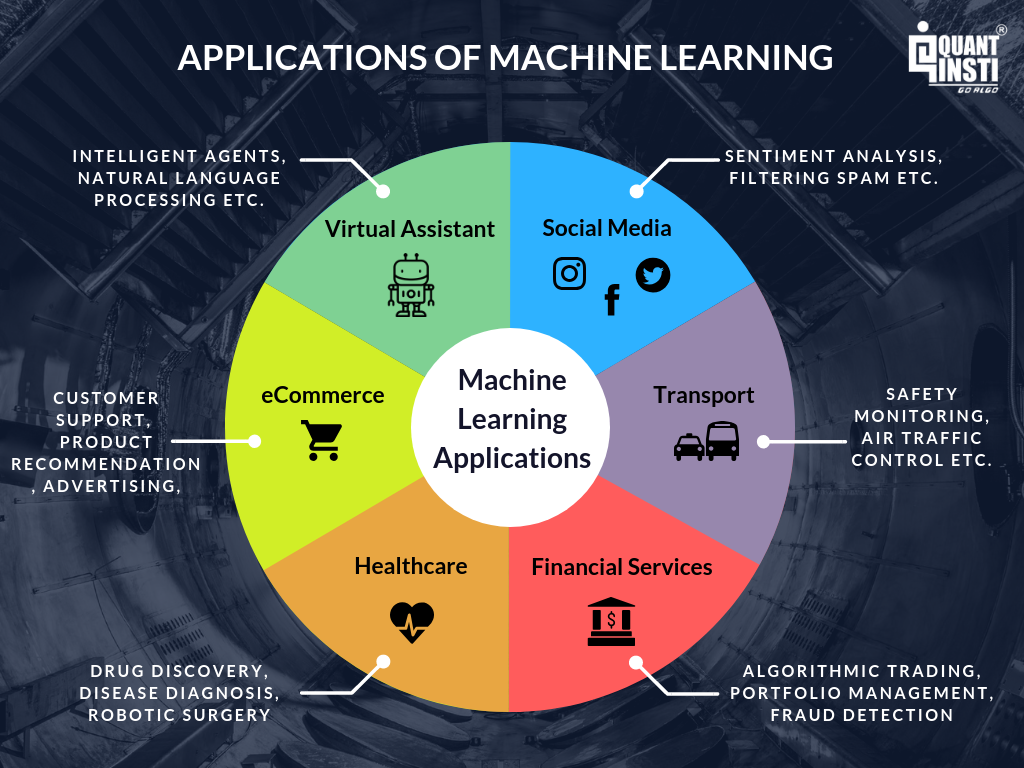
Healthcare
Machine learning helps diagnose diseases and predict patient outcomes. Personalized medicine tailors treatments based on individual data. For example, models can analyze symptoms to detect early signs of illnesses like cancer, improving patient care.
Finance
It detects fraudulent transactions and aids in algorithmic trading. Machine learning models also assess credit risk. For instance, banks use these models to decide loan eligibility, reducing the chances of bad loans.
Retail
Retailers use it for product recommendations and managing inventory. For example, online stores suggest items based on your browsing history. This enhances customer experience and streamlines operations, leading to better sales.
Self-Driving Cars
Machine learning powers autonomous vehicles. It enables navigation, obstacle detection, and decision-making on the road. For instance, these systems analyze traffic patterns to make real-time driving decisions, ensuring safety and efficiency.
Education
In education, machine learning personalizes learning experiences. For example, adaptive learning platforms analyze student performance and suggest tailored study plans. This approach helps students learn at their own pace and improves outcomes.
Entertainment
Streaming services like Netflix and Spotify use machine learning for content recommendations. By analyzing user preferences and behaviours, these platforms suggest shows, movies, or songs, enhancing user satisfaction and engagement.
Manufacturing
In manufacturing, machine learning improves quality control. For instance, it detects defects in products by analyzing images from production lines. This ensures consistency and reduces waste, leading to higher efficiency.
Agriculture
Farmers use machine learning for precision agriculture. For example, models analyze weather data and soil conditions to optimize planting schedules and irrigation. This approach increases crop yield and reduces resource use.
8. Challenges and Limitations
Data Quality
Poor-quality data can lead to inaccurate predictions. Cleaning data is essential but time-consuming. If the data contains biases or errors, the model’s performance suffers. Ensuring high-quality data is a fundamental step in the process.
Overfitting and Underfitting
Overfitting occurs when a model learns too much from training data, failing to generalize. Underfitting happens when the model is too simple to capture patterns. Balancing complexity is key to creating effective models.
Ethical Concerns
Machine learning raises issues like bias and privacy. For instance, a biased dataset can result in unfair decisions, like denying loans to specific groups. Ensuring fairness and accountability is crucial to address these concerns.
9. Getting Started with Machine Learning
Machine learning (ML) is a way for computers to learn from data and make decisions without being specifically programmed for every task. Think of it as teaching a computer to recognize patterns, just like we learn from examples. Now, here’s how you can start learning about machine learning:
1. Learn the Basics
- What does this mean?
Before diving into machine learning, you need to understand some basic concepts. It’s like learning the alphabet before writing a story. - How can you do this?
Start by taking beginner-friendly online courses or tutorials. Websites like Coursera and edX are great places to find these. They have step-by-step lessons, often with videos and examples, to make learning easy and fun. - What will you learn?
These courses teach you fundamental topics like:- What is machine learning?
- How does a computer learn from data?
- Basic tools and techniques used in ML.
2. Hands-on Practice
- What does this mean?
Learning isn’t just about reading or watching videos. You need to practice by actually working on real problems. Imagine trying to learn basketball just by watching games—you won’t improve unless you play yourself! - How can you do this?
Start small and simple. Platforms like Kaggle provide datasets (collections of information) and challenges. For example, you might analyze data to predict house prices or categorize emails as spam or not spam. - Why is this important?
Practising helps you understand how machine learning works in the real world. It also makes you more confident and skilled at solving problems.
3. Join Communities
- What does this mean?
Communities are groups of people learning and working together. They can help you when you’re stuck, share tips, and even inspire you to try new things. - How can you do this?
Join online forums and groups like:- Reddit communities for machine learning.
- Discord or Slack groups for beginners.
- Kaggle forums where people share ideas.
- Why join a community?
- You’ll learn faster because you can ask questions and get help from experienced people.
- It’s more fun to learn with others who share your interest.
- You might find mentors or teammates to work on projects together.
Conclusion
Machine learning is not just transforming industries; it is also driving innovation in ways that were unimaginable just a few decades ago. From personalized recommendations to autonomous vehicles, its wide range of applications demonstrates its impact on shaping the future. To fully embrace this field, it is essential to first gain a solid understanding of its basics, as this serves as the foundation for more advanced exploration.
Although the journey may seem complex initially, starting with small projects and practising consistently will help you build confidence over time. Moreover, by engaging with real-world data and projects, you can uncover its endless possibilities. Ultimately, staying curious and embracing challenges will be crucial for mastering this exciting domain. With determination, persistence, and a willingness to learn, you can harness the immense power of machine learning and thrive in this rapidly evolving field.
Curious to dive deeper into the world of machine learning? Don’t miss these handpicked resources—explore them now and supercharge your learning journey!
Metrics used for evaluating regression models
Need and application of regression in machine learning
What is feature scaling in machine learning
Data preprocessing methods in machine learning
Frequently faced issues in machine learning
Uses of machine learning in real life